vLLM V1 Engine Design Ⅰ: The Excution Loop
vLLM is a high-perfomance, user-friendly library for LLM serving. It has rapidly gained widespread popularity among individual users, developers and enterprises since its launch. As the serving latency continues to decrease, CPU overhead has become a clear bottleneck to further accerating model serving on the vLLM V0 engine core. One of the key motivations for migrating to the vLLM V1 engine core is to address this bottleneck
vLLM V1 isolates CPU work into two dedicated processes. One process handles user-facing API requests, HTTP/TCP communication, detokenization, etc.; the other spins in a busy loop scheduling and dispatching GPU workloads. By separating web I/O and token processing from GPU dispatch, this design keeps the accelerator busy and minimizes GPU idle time.
Offline batching and online streaming are two modes of using the vLLM inference engine. Offline batching is driven by the Python LLM class. It exposes the following APIs:
generate()is for autoregressive text generation—given a prompt, it produces a completion.chat()is for conversation. It supports conversation context defined like1
2
3
4conversation = [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
]A chat template then serializes this history into a single prompt string using the model’s special tokens. Under the hood,
chat()calls thegenerate()routine to complete the next assistant turn.Other APIs:
beam_search()encode()embed()classify()
The calls to these functions are blocking — it will block until the full output is returned.
AsyncLLM , on the other hand, is built on top of Python’s asyncio and is aimed for LLM serving or online streaming. vLLM provides an implementation of OpenAI compatible API server exposing entrypoints such as /v1/completions and /v1/chat/completions which calls generate() and chat() on AsyncLLM under the hood.
Offline Batching
The excution loop of running a traditional text-only offline LLM chat is shown in Figure 1 where the arrows in the figure indicate data flow and ↻ indicates an infinite loop. An individual thread has a gray background.
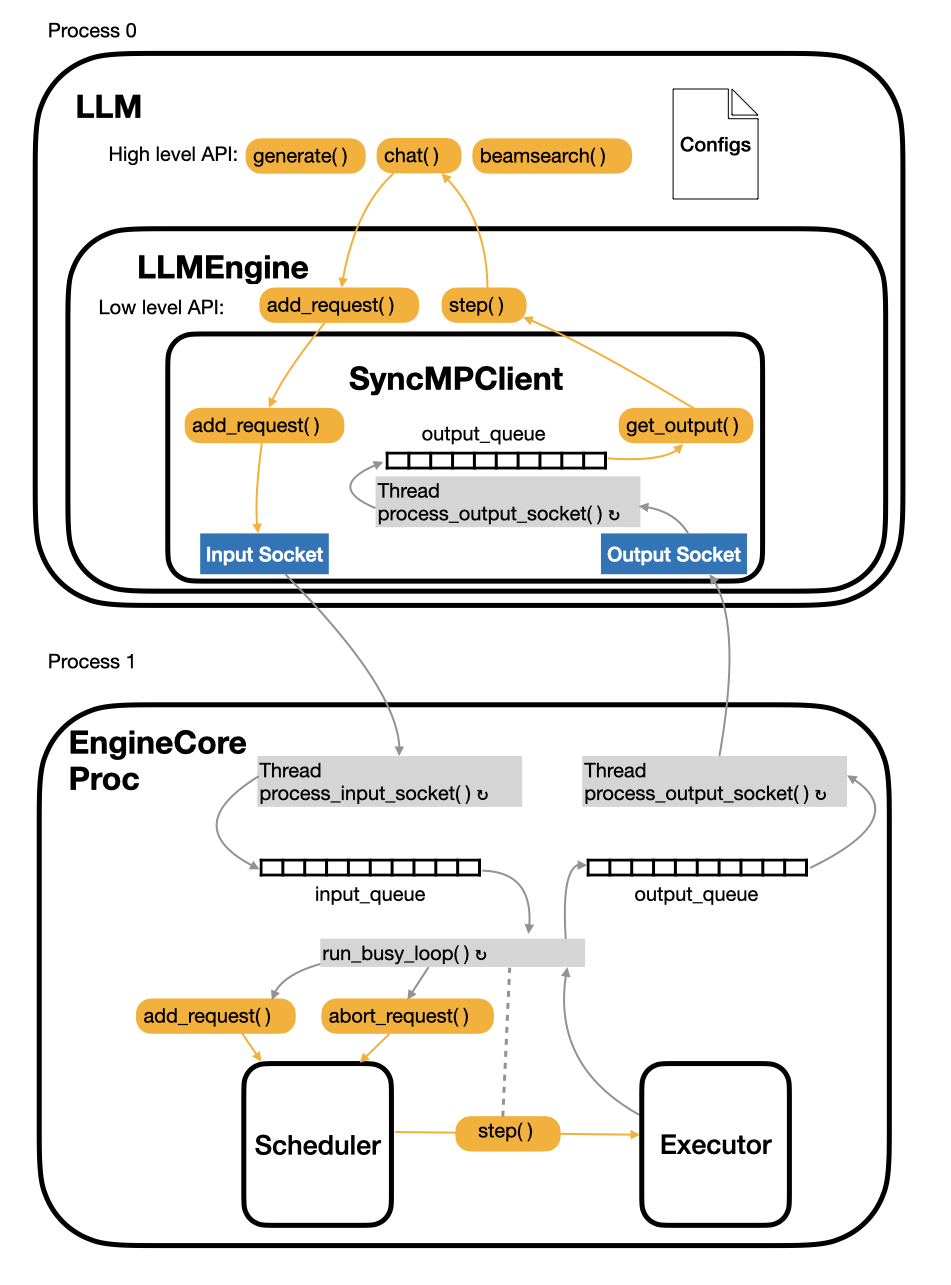
Internally, LLM submits user requests via add_request() and generates outputs with step(), both methods are defined on LLMEngine. While the V1 LLMEngine preserves the V0 API surface for backward compatibility, it offloads most of the request handling and output handling to the underlying SyncMPClient .
vLLM offline batching follows the producer-consumer concurrency paradigm. Each thread spends most of their time waiting on I/O-polling sockets or blocking on queue.get() — during which they release the GIL and let other threads run.
Python Multi-threading Model
Python provides OS-level multithreading via thethreading module. Each Thread object maps to a native thread with its own stack and execution context.
However, within a single Python process, only one thread can execute Python bytecode at a time because every thread must hold the Global Interpreter Lock (GIL).
I/O-bound workloads can benefit from multithreading—threads release the GIL while waiting on I/O—but CPU-bound tasks cannot achieve true parallel execution.
This explains why vLLM v1 chooses to put model execution in a separate process instead of a thread — circumventing the GIL to get real parallelism. This is at the expense of inter-process data copies via message queues and added architectural complexity.
But in the other hand, this multi-process design decouples client handling from model execution, even allowing them to run on separate machines if desired.
SyncMPClient - as its name suggests—serves as the communication client for the backend execution ‘server’ process EngineCoreProc .
- Two
ZMQsockets are used for inter-process-communication. add_request( )serializes and packages the user’s inference request, then sends it over the input socket.get_output()simply blocks onoutput_queue.get(), returning the next available response.- A dedicated background thread
process_output_socket()continuously polls the output socket, deserializes any incoming responses, and enqueues them into an internaloutput_queue
EngineCoreProc runs 3 infinite-loop threads in a single process:
- The main thread dequeues requests from
input_queueand callsadd_request( )orabort_request( )depending on the request type. It invokesstep()to feed the scheduler’s output into the inference engine. - Input-polling thread spins reading the input socket and deserializes each incoming message and enqueues it onto
input_queue - Output-dispatch thread blocks on output_queue until results appear and sends serialized result over the output socket.
queue— A synchronized queue class
The input_queue and the output_queue in vLLM V1 architecture are both of instance of queue.Queue. It is a FIFO queue which ensures thread safety when multiple threads are excuting push() or get() concurrently.
The get() method removes and returns an item from the queue. If the option block is set to be True (which is by default), it will block the code execution until there’s an item is available in the queue. If the queue is empty, get() enters an uninterruptible wait on an internal lock—releasing the GIL so other threads can run—before returning the enqueued item.
Online Streaming
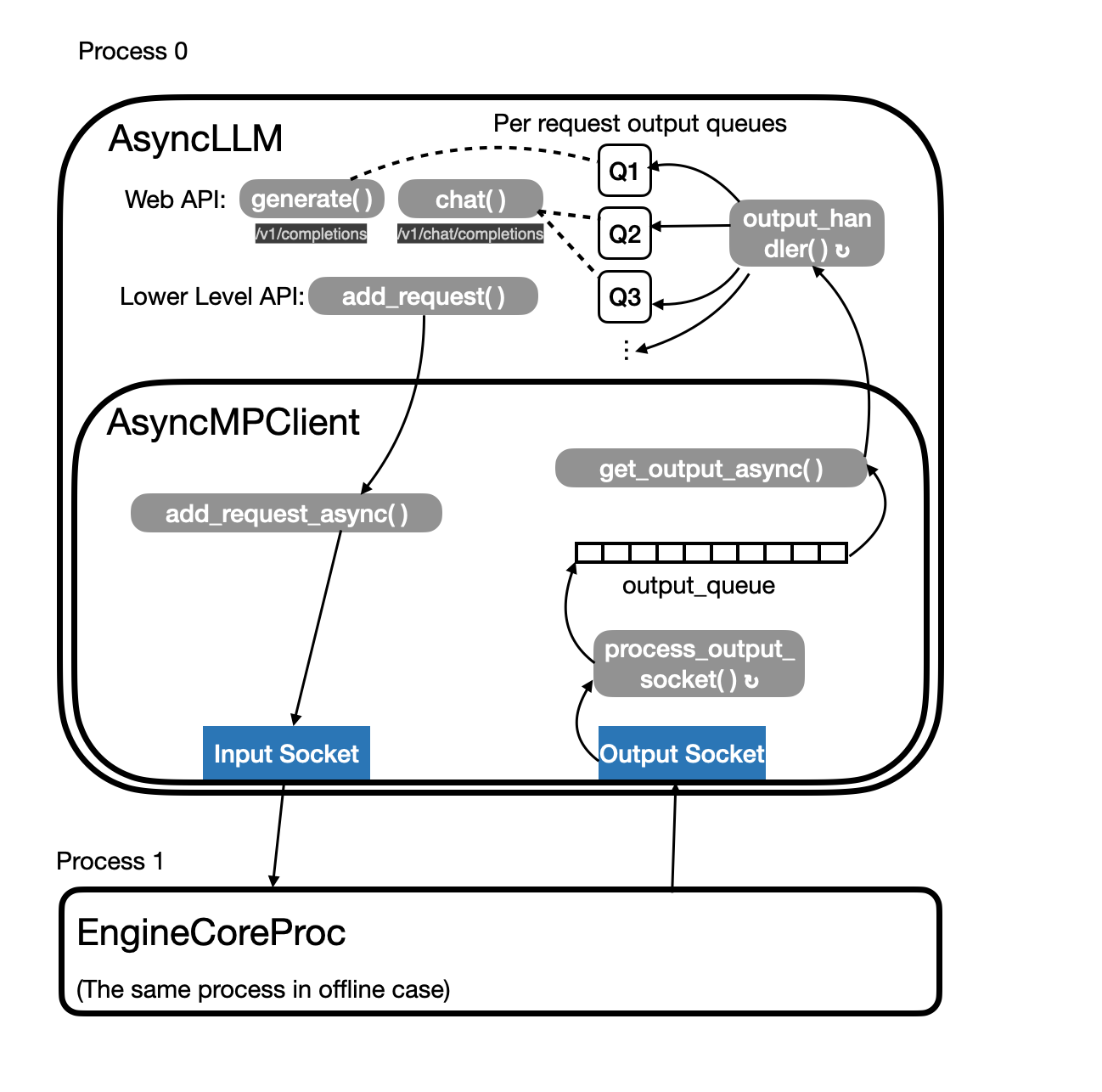
In online streaming scenarios, each request has its own lifecycle and must be driven incrementally rather than in one shot via generate() or chat(). To support this, vLLM uses Python’s asyncio:
- Per‐request coroutines: Each incoming request is handled by its own coroutine on a single event loop. Because coroutine switches don’t require releasing the GIL, they’re much lighter than threads.
- Per‐request queues:
AsyncLLMmaintains a dedicated output queue for each request. output_handler()loop: A background coroutine continuously awaitsAsyncMPClient.get_output_async(), then routes and appends each new chunk of data into the appropriate request queue. By aggregating new data with what’s already in the queue, it avoids the overhead of sending each token or chunk separately.- AsyncMPClient: Functionally analogous to
SyncMPClient, but replaces its blocking threads with non-blocking coroutines andawaitcalls.